(MY)SQL JOIN 가이드 for Beginer
TL;DR
- Legacy 서비스 유지보수를 하면서 Model에서 SQL을 직접 작성하면서 정리했던 JOIN의 정의 및 자주 사용되는 문법 그리고 장점에 대해 다뤄보겠습니다.
JOIN?
JOIN은 관계형 데이터베이스에서 여러 테이블의 데이터를 결합하는 핵심 기능입니다. 테이블 간 관계는 1:1, 1:N, N:M으로 구분됩니다.
이해하기
이해를 쉽게 돕게하기 위해 가상의 테이블을 정의한 후 해당 데이터를 기준으로 설명하겠습니다.
INIT Database
CREATE TABLE Customers (
c_id INT PRIMARY KEY,
c_name VARCHAR(100) NOT NULL,
c_email VARCHAR(100) UNIQUE NOT NULL,
c_phone VARCHAR(20),
address VARCHAR(200),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
CREATE TABLE Products (
p_id INT PRIMARY KEY,
p_name VARCHAR(100) NOT NULL,
p_price DECIMAL(10, 2) NOT NULL,
description TEXT,
stock_quantity INT NOT NULL DEFAULT 0,
category VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
CREATE TABLE Orders (
o_id INT PRIMARY KEY,
o_date DATE NOT NULL,
o_total_amount DECIMAL(10, 2) NOT NULL,
status VARCHAR(20) NOT NULL,
c_id INT NOT NULL,
shipping_address VARCHAR(200),
payment_method VARCHAR(50),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
CREATE TABLE OrderDetails (
o_d_id INT PRIMARY KEY,
o_id INT NOT NULL,
p_id INT NOT NULL,
quantity INT NOT NULL,
unit_price DECIMAL(10, 2) NOT NULL,
subtotal DECIMAL(10, 2) GENERATED ALWAYS AS (quantity * unit_price) STORED,
discount DECIMAL(10, 2) DEFAULT 0.00
);
INSERT INTO Customers (c_id, c_name, c_email, c_phone, address) VALUES
(1, 'Noah', 'noah@gmail.com', '111-222-3333', '123 Apple St, New York, NY 10001'),
(2, 'Kyle', 'kyle@gmail.com', '444-555-6666', '456 Banana Ave, Los Angeles, CA 90001'),
(3, 'Chuck', 'chuck@gmail.com', '777-888-9999', '789 Cherry Ln, Chicago, IL 60601');
INSERT INTO Products (p_id, p_name, p_price, description, stock_quantity, category) VALUES
(1, 'iPhone', 10000.00, 'Latest model iPhone with advanced features', 100, 'Electronics'),
(2, 'iPad', 20000.00, 'Powerful and versatile iPad for work and play', 50, 'Electronics'),
(3, 'AirPod', 30000.00, 'Wireless earbuds with exceptional sound quality', 200, 'Accessories');
INSERT INTO Orders (o_id, o_date, o_total_amount, status, c_id, shipping_address, payment_method) VALUES
(1, '2024-08-14', 100000.00, 'Pending', 1, '123 Apple St, New York, NY 10001', 'Credit Card'),
(2, '2024-08-15', 300000.00, 'Delivered', 2, '456 Banana Ave, Los Angeles, CA 90001', 'PayPal'),
(3, '2024-08-16', 60000.00, 'Processing', 2, '456 Banana Ave, Los Angeles, CA 90001', 'Debit Card');
INSERT INTO OrderDetails (o_d_id, o_id, p_id, quantity, unit_price, discount) VALUES
(1, 1, 1, 10, 10000.00, 0.00),
(2, 2, 1, 10, 10000.00, 0.00),
(3, 2, 2, 10, 20000.00, 0.00),
(4, 3, 3, 5, 30000.00, 5000.00);SQL test website
- 다음 사이트에서 SQL 테스트가 가능합니다.
- 위 SQL을 상단 INIT database에 고정 후 하단에 실습하기에서 제공되는 예제 SQL을 QUERY database에 입력해 테스트가 가능합니다.
- SQL Fiddle 🔗
왜 사용할까?
- 데이터 통합: 여러 테이블에 분산된 관련 데이터를 하나의 결과 집합으로 결합합니다.
- 정규화된 데이터 활용: 정규화로 분리된 테이블의 데이터를 효율적으로 조회할 수 있습니다.
- 데이터 중복 감소: 데이터를 여러 테이블로 나누어 저장함으로써 중복을 줄이고 일관성을 유지합니다.
- 복잡한 쿼리 작성: 여러 테이블의 데이터를 조합하여 복잡한 비즈니스 로직을 구현할 수 있습니다.
- 데이터 분석 용이: 다양한 각도에서 데이터를 분석하고 인사이트를 얻을 수 있습니다.
이러한 이유들로 JOIN은 관계형 데이터베이스에서 핵심적인 기능으로 사용됩니다.
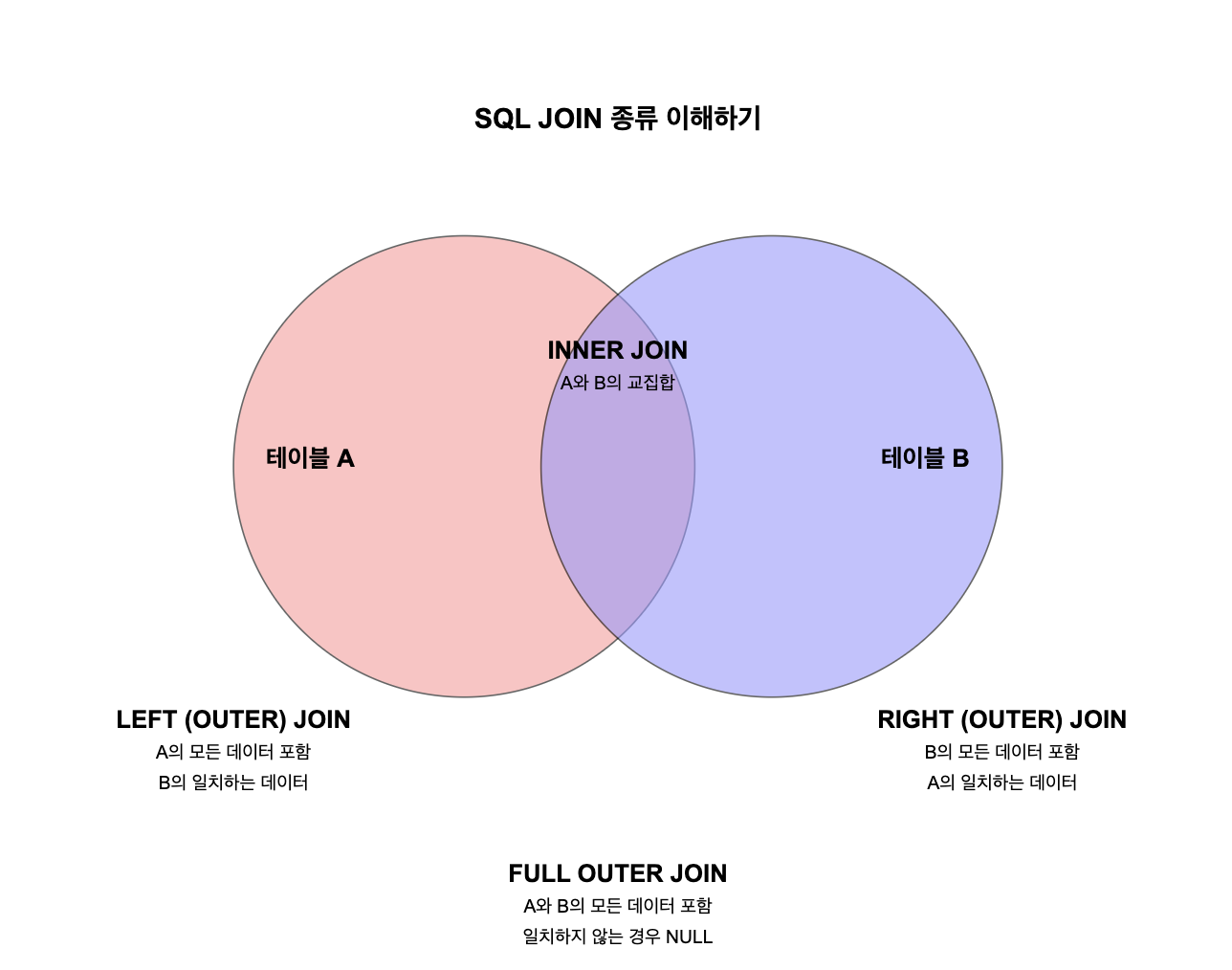
1. INNER JOIN
- 두 테이블에서 조건이 일치하는 레코드만 결과로 반환합니다.
- 양쪽 테이블에서 일치하는 데이터만 가져오는 교집합 개념입니다.
2. LEFT (OUTER) JOIN
- 왼쪽 테이블의 모든 레코드와 오른쪽 테이블에서 조건이 일치하는 레코드를 반환합니다.
- 일치하는 데이터가 오른쪽 테이블에 없으면 NULL 값으로 채워집니다.
3. RIGHT (OUTER) JOIN
- 오른쪽 테이블의 모든 레코드와 왼쪽 테이블에서 조건이 일치하는 레코드를 반환합니다.
- 일치하는 데이터가 왼쪽 테이블에 없으면 NULL 값으로 채워집니다.
4. FULL (OUTER) JOIN
- 양쪽 테이블의 모든 레코드를 반환합니다.
- 일치하는 데이터가 없는 경우 해당 부분은 NULL 값으로 채워집니다.
- MySQL은 FULL OUTER JOIN을 직접 지원하지 않지만, LEFT JOIN과 RIGHT JOIN, 그리고 UNION을 조합하여 구현할 수 있습니다.
실습하기
- 모든 JOIN에 대해서가 아닌 자주 사용되는 JOIN에 대해서만 예시 query를 작성해 소개 드리겠습니다.
QUERY database
INNER JOIN
SELECT
c.c_name AS customer_name,
o.o_id AS order_id,
o.o_date AS order_date,
p.p_name AS product_name,
od.quantity,
od.unit_price,
od.subtotal,
(od.subtotal - od.discount) AS final_price
FROM
Customers c
INNER JOIN Orders o ON c.c_id = o.c_id
INNER JOIN OrderDetails od ON o.o_id = od.o_id
INNER JOIN Products p ON od.p_id = p.p_id
WHERE
o.o_date BETWEEN '2024-08-01' AND '2024-08-31'
AND p.category = 'Electronics'
ORDER BY
o.o_date DESC, od.subtotal DESC;- 이 쿼리는 고객, 주문, 주문 상세, 제품 테이블을 모두 INNER JOIN하여 연결합니다.
- 2024년 8월에 발생한 ‘Electronics’ 카테고리 제품 주문에 대한 상세 정보를 조회합니다.
- 결과는 주문 날짜의 내림차순, 그 다음으로 소계의 내림차순으로 정렬됩니다.
- 최종 가격(final_price)은 소계에서 할인을 뺀 값으로 계산됩니다.
LEFT (OUTER) JOIN
SELECT
c.c_name AS customer_name,
COALESCE(COUNT(DISTINCT o.o_id), 0) AS total_orders,
COALESCE(SUM(od.quantity), 0) AS total_items_purchased,
COALESCE(SUM(od.subtotal - od.discount), 0) AS total_spent,
MAX(o.o_date) AS last_order_date,
GROUP_CONCAT(DISTINCT p.category SEPARATOR ', ') AS purchased_categories
FROM
Customers c
LEFT JOIN Orders o ON c.c_id = o.c_id
LEFT JOIN OrderDetails od ON o.o_id = od.o_id
LEFT JOIN Products p ON od.p_id = p.p_id
GROUP BY
c.c_id, c.c_name
HAVING
COUNT(DISTINCT o.o_id) >= 0
ORDER BY
total_spent DESC, total_orders DESC;- 이 쿼리는 모든 고객에 대해, 주문이 없는 고객도 포함하여 주문 통계를 생성합니다.
- LEFT JOIN을 사용하여 주문이 없는 고객도 결과에 포함시킵니다.
- 각 고객별로 총 주문 수, 구매한 총 상품 수, 총 지출액, 마지막 주문 날짜, 구매한 제품 카테고리를 계산합니다.
- COALESCE 함수를 사용하여 주문이 없는 경우 0으로 표시합니다.
- GROUP_CONCAT 함수를 사용하여 고객이 구매한 모든 고유한 제품 카테고리를 쉼표로 구분된 목록으로 만듭니다.
- 결과는 총 지출액과 총 주문 수의 내림차순으로 정렬됩니다.
Conclusion
- 지금까지 SQL JOIN의 기본 개념과 주요 유형에 대해 알아보았습니다. JOIN은 관계형 데이터베이스에서 데이터를 효과적으로 결합하고 분석하는 데 필수적인 도구입니다. 위 실습에서 제공되는 SQL을 논리적으로 분석 및 학습한다면 간단한 JOIN 유지보수에는 문제가 없을것이라 판단됩니다. 마지막으로, JOIN을 사용할 때 주의해야 할 점과 유용한 팁을 정리해 보겠습니다.
1. 성능 최적화
필요한 테이블만 JOIN 해서 쿼리 성능을 향상시켜야합니다. JOIN 컬럼에 적절한 인덱스를 생성하면 쿼리 속도를 크게 향상시킬 수 있습니다. 그리고 가능하면 작은 테이블을 큰 테이블에 JOIN하는 것이 효율적입니다.
2. NULL 값 처리
OUTER JOIN 사용 시 NULL 값 처리에 특히 주의해야 합니다. COALESCE 또는 IFNULL 함수를 사용하여 NULL 값을 적절히 처리하고, NULL 값 비교 시 IS NULL 또는 IS NOT NULL 연산자를 사용해야합니다.
3. 데이터 정확성 확인
JOIN 조건을 정확히 설정했는지 항상 확인해야합니다. 복잡한 JOIN 쿼리의 경우, 단계별로 결과를 확인하며 작성하는 것이 도움됩니다.
4.가독성 향상
복잡한 JOIN 쿼리는 적절한 들여쓰기와 주석을 사용하여 가독성을 높이고, 서브쿼리나 CTE(Common Table Expression)를 활용하여 복잡한 쿼리를 구조화할 수 있습니다.
5.지속적인 학습과 실습
데이터베이스의 실행 계획을 분석하여 쿼리의 성능을 이해하고 개선하세요. 다양한 JOIN 기법(SELF JOIN, CROSS JOIN 등)을 익히고 적절한 상황에 활용하세요.